Manoj Panduraj
DevOps Engineer | Site Reliability Engineer | Cloud Engineer | Cloud Architect
Kubernetes • Terraform • AWS • GCP • CI/CD • Observability
Building reliable cloud platforms, scalable Kubernetes systems, and production-ready automation.

Professional Snapshot
GCP-focused DevOps/SRE engineer with 3 years of experience supporting production cloud platforms and Kubernetes workloads. Strong in IaC, observability, cloud migration, and security-by-design.
GKE / EKS
Production Kubernetes Management
AWS → GCP
Enterprise Migration Support
Terraform
Secure Infrastructure as Code
Splunk + NR
Observability & Incident Response
Professional Summary
I am a GCP-focused DevOps and SRE engineer with 3.5+ years of experience architecting, automating, and supporting production-grade cloud platforms across enterprise environments. My passion lies in building resilient, scalable, and secure infrastructure that empowers development teams and delivers seamless user experiences.
I have strong hands-on expertise in Kubernetes (GKE/EKS), Terraform (Infrastructure as Code), CI/CD automation, cloud networking, and production observability. I have contributed to large-scale AWS-to-GCP migration initiatives, ensuring smooth cutovers, operational stability, and high platform availability throughout critical transitions.
Beyond infrastructure engineering, I specialize in monitoring, logging, and reliability engineering using tools such as Splunk, New Relic, Prometheus, and Grafana. I focus heavily on proactive incident management, root cause analysis (RCA), performance optimisation, and reducing operational toil through automation.
My technical background also includes cloud security and governance practices such as IAM, RBAC, secrets management, and infrastructure hardening across cloud-native environments. I enjoy working on high-impact systems where reliability, scalability, and operational excellence are critical.
Work History
Intern
Aramark UK · Contract
-
Supporting day-to-day operations across Chessington World of Adventures Resort and Merlin Entertainment sites. -
Building internal tooling (Shift-Ops) to replace manual spreadsheet-based shift and payroll tracking.
Customer Service Representative
John Lewis & Partners · Contract
-
Assisted customers with product queries, in-store navigation, and service requests in a high-volume retail environment. -
Upheld partnership values through consistent service quality and team coordination across daily operations.
DevOps Engineer / Cloud Platform Engineer
Applied Cloud Computing · Full-time
-
Managed and scaled distributed systems across cloud environments, provisioning with Terraform and config-as-code. -
Built and operated observability with Prometheus, Grafana, Loki, Mimir, and OpenTelemetry for metrics, distributed tracing, monitoring, and alerting. -
Authored and released Python and Bash automation for provisioning, deployment, and monitoring at scale. -
Operated Kubernetes clusters with Helm, deploying and supporting application stacks end to end. -
Contributed to capacity planning and performance tuning to keep services highly available. -
Applied Linux and networking fundamentals to troubleshoot HTTP, DNS, and TCP/IP issues. -
Evaluated and integrated new observability and automation technologies to improve system reliability, security, and performance. -
Collaborated on code, infrastructure, and design reviews, driving process improvements.
Site Reliability Engineer
Randstad India Private Limited · Full-time
-
Led an AWS-to-GCP migration of 130+ microservices across geographically dispersed environments, sustaining 99.9%+ availability. -
Built Prometheus, Grafana, and Loki telemetry pipelines to detect failing hosts and services quickly. -
Automated build, deployment, and monitoring to remove manual, repetitive operational work. -
Ran root cause analysis and disaster-recovery and rollback exercises to strengthen resilience. -
Reduced infrastructure cost by approximately 25% while sustaining reliability and performance. -
Used scale and load testing to measure, tune, and optimise system performance. -
Monitored host and service health to detect failures within seconds and trigger automated alerting. -
Partnered with development teams to design resilient, scalable infrastructure solutions.
Software Test Engineer / Subject Matter Expert
Chegg India Private Limited
-
Applied SDLC, STLC, and testing methodologies including functional, system, regression, performance, and web services testing. -
Integrated Selenium with TestNG and Apache POI for data-driven automation, and developed detailed test plans, scenarios, and test cases. -
Performed API testing using Postman and wrote complex SQL queries for data validation, tracking defects through Bugzilla and Jira. -
Provided expert guidance as a Subject Matter Expert in Computer Science, delivering high-quality solutions across core CS topics. -
Operated as an independent contractor, managing workload and deadlines against fluctuating student demand.
Projects
InfraWatch - SRE Monitoring Platform (Grafana Based)
Production Observability • GitOps • Incident Response
Platform Overview
Production-style observability platform built with Prometheus, Grafana, Loki, Promtail, Alertmanager, Slack, Docker, and GitHub Actions for real-time monitoring, centralized logging, alerting, GitOps deployment, and incident response automation across cloud and local systems.
Demo Access
Username: demo_user
Password: demo_user
Use these demo credentials to explore the live monitoring platform.
3D Portfolio Website
Cloud Visualization • Interactive UI • Frontend Engineering
An immersive digital environment designed to bridge the gap between complex DevOps concepts and high-performance frontend engineering. Features a custom 3D engine and a reactive UI shell, hosted on Google Cloud Platform.
Performance
Optimized RequestAnimationFrame loop & hardware-accelerated GSAP animations.
Graphics
Direct GPU-accelerated 3D rendering for complex particle systems and effects.
Load Time
Asset compression, lazy loading, and low-latency GCP hosting.
Responsive
Mobile-first CSS and dynamic 3D camera resize listeners.
Shift-Ops - Payroll Tracker
Full-Stack • React + FastAPI • GCP Deployment
Personal shift-tracking web app for two Aramark employees to log hours, calculate pay, and monitor weekly and pay-period targets. Replaces manual spreadsheets with a mobile-first React + FastAPI app - auto break deductions, Aramark payroll calendar, and CI/CD to GCP via GitHub Actions.
Users
Manoj & Jothesh - each user sees only their own shifts via user_id isolation on every API endpoint.
App Tabs
Log, Overview (donut chart), Shifts table, Salary (pay periods), Schedule (Aramark W02–W52 tax calendar).
Hourly Rate
30 min break auto-deducted if shift > 6h. 2-week Aramark pay cycles anchored to Sat 14 Mar 2026.
Hosted
Nginx serves React build + proxies /api/ to FastAPI :8000. Systemd keeps backend alive. GitHub Actions CI/CD on push.
Multi-Environment Kubernetes Deployment Platform
Designed a reusable deployment framework for development, staging, and production Kubernetes environments using Helm, Terraform, and GitHub Actions.
Standardized releases across environments with repeatable infrastructure provisioning. Integrated CI/CD automation with secure secrets handling and rollout validation.
Cloud Migration Readiness & Cutover Automation
Built a migration support workflow for AWS to GCP transitions covering provisioning, validation checklists, and post-cutover monitoring readiness.
Created Terraform templates for faster and safer cloud resource setup. Defined rollback-aware deployment steps and smoke-test verification.
Observability & Incident Response Dashboard Suite
Implemented operational dashboards and alert tuning workflows with Splunk, New Relic, and Cloud monitoring tools for production systems.
Centralized logs, metrics, and alert signals for faster diagnosis. Reduced noise through alert tuning and prioritization logic.
Secure Infrastructure as Code Modules
Developed modular Terraform components for cloud networking, IAM, and workload deployment with security-by-design principles.
Enabled repeatable provisioning across AWS and GCP environments. Implemented automated policy checks (Sentinel/OPA) for IaC compliance.
InfraWatch - SRE Monitoring Platform
A production-style observability platform built using Prometheus, Grafana, Loki, Promtail, Alertmanager, Slack, Docker, and GitHub Actions for real-time infrastructure monitoring, centralized logging, alerting, and incident response automation.
Metrics
GCP VM, MacBook, website, and Prometheus health monitoring.
Logs
Centralized Docker and system logs using Loki and Promtail.
Alerts
Alertmanager sends real-time Slack alerts and recovery notices.
Infrastructure Flow
MacBook
Node Exporter
GCP VM
Docker Stack
Prometheus
Metrics
Grafana
Dashboards
Slack
Alerts
Grafana Dashboard Gallery
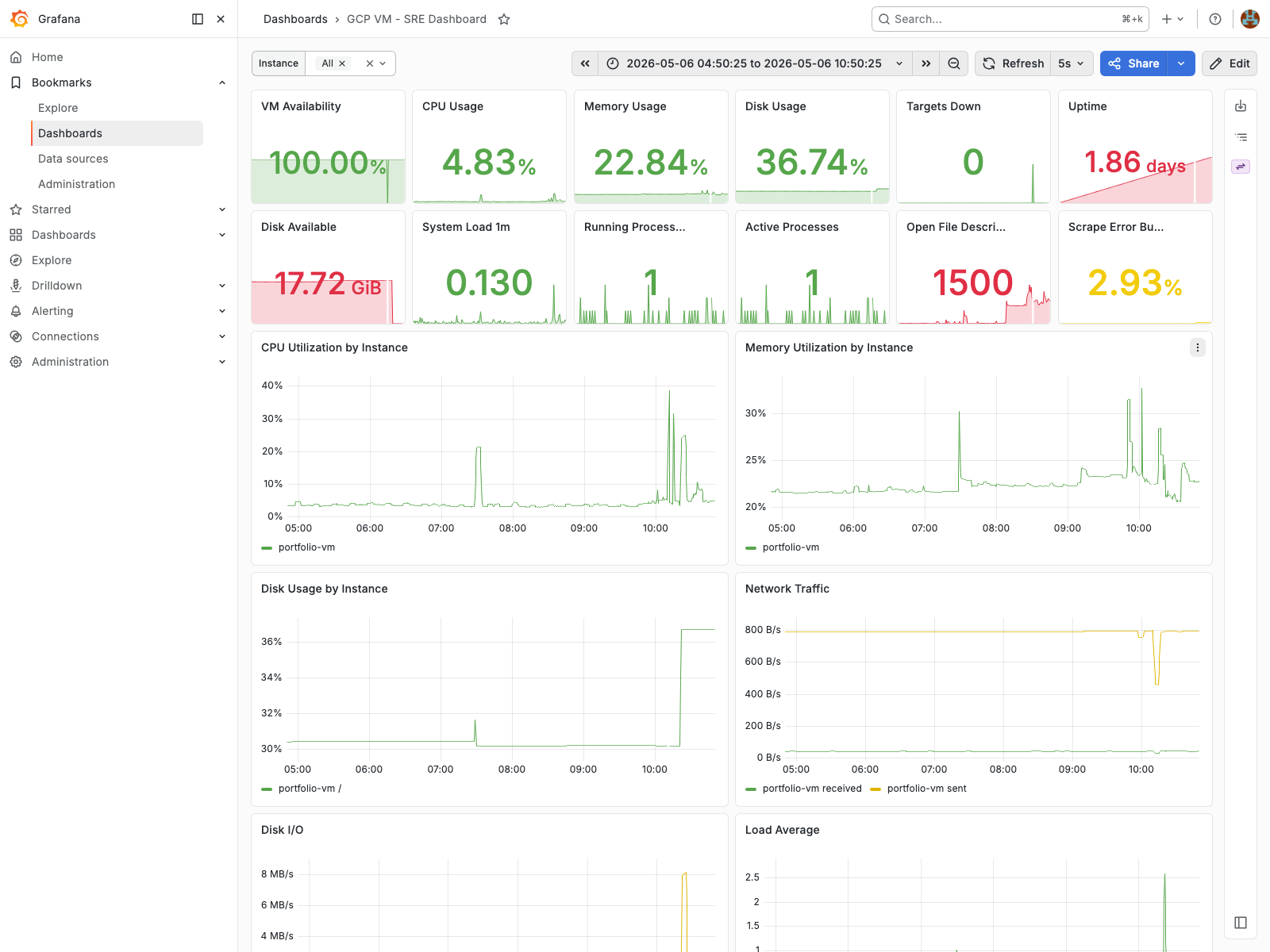
GCP VM Dashboard
CPU, memory, filesystem, load average, network traffic, SLA, and infrastructure health.
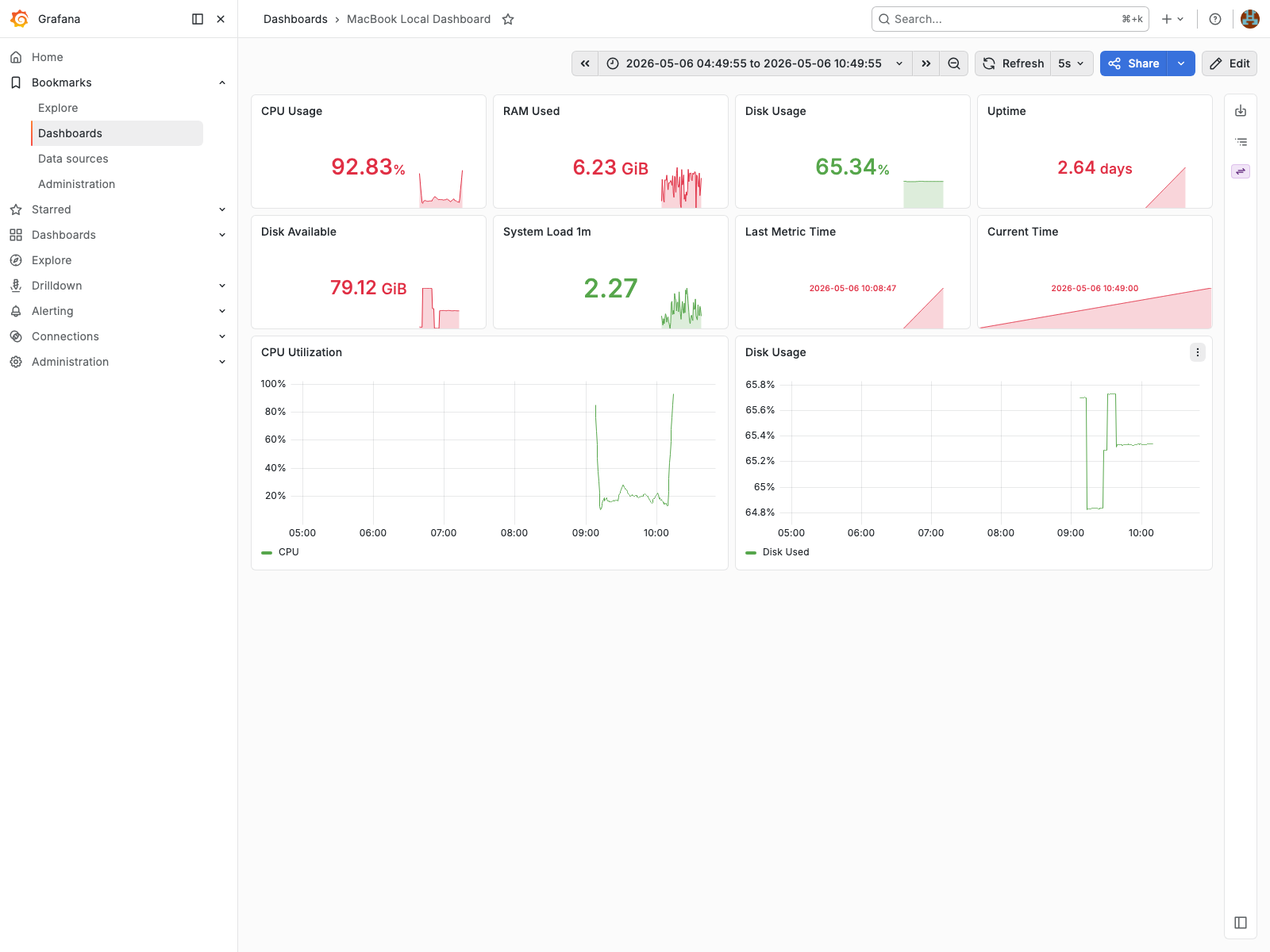
MacBook Monitoring
Local machine observability using secure SSH reverse tunneling.
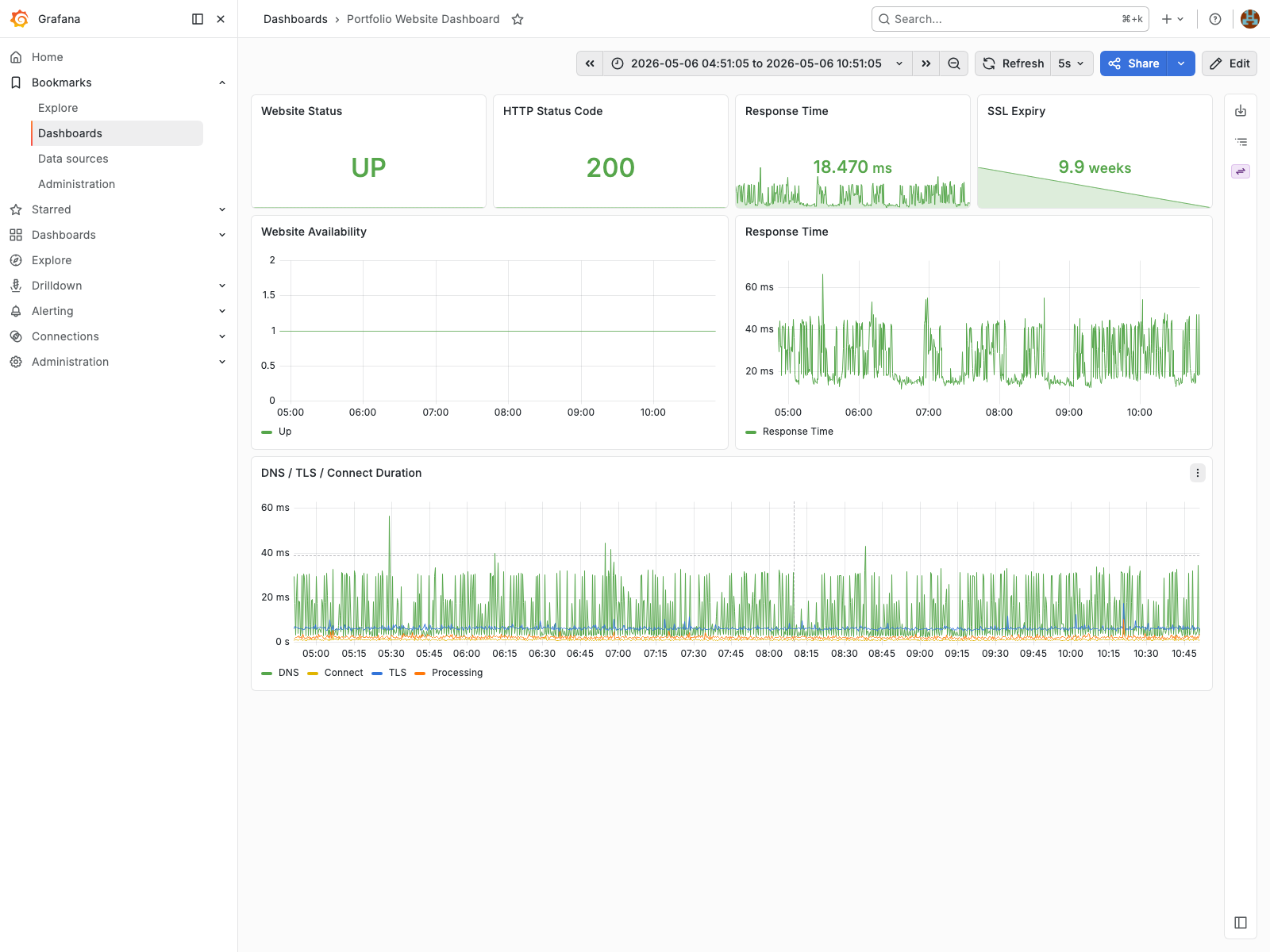
Website Uptime Dashboard
Blackbox monitoring for uptime, latency, HTTP status, and SSL expiry.
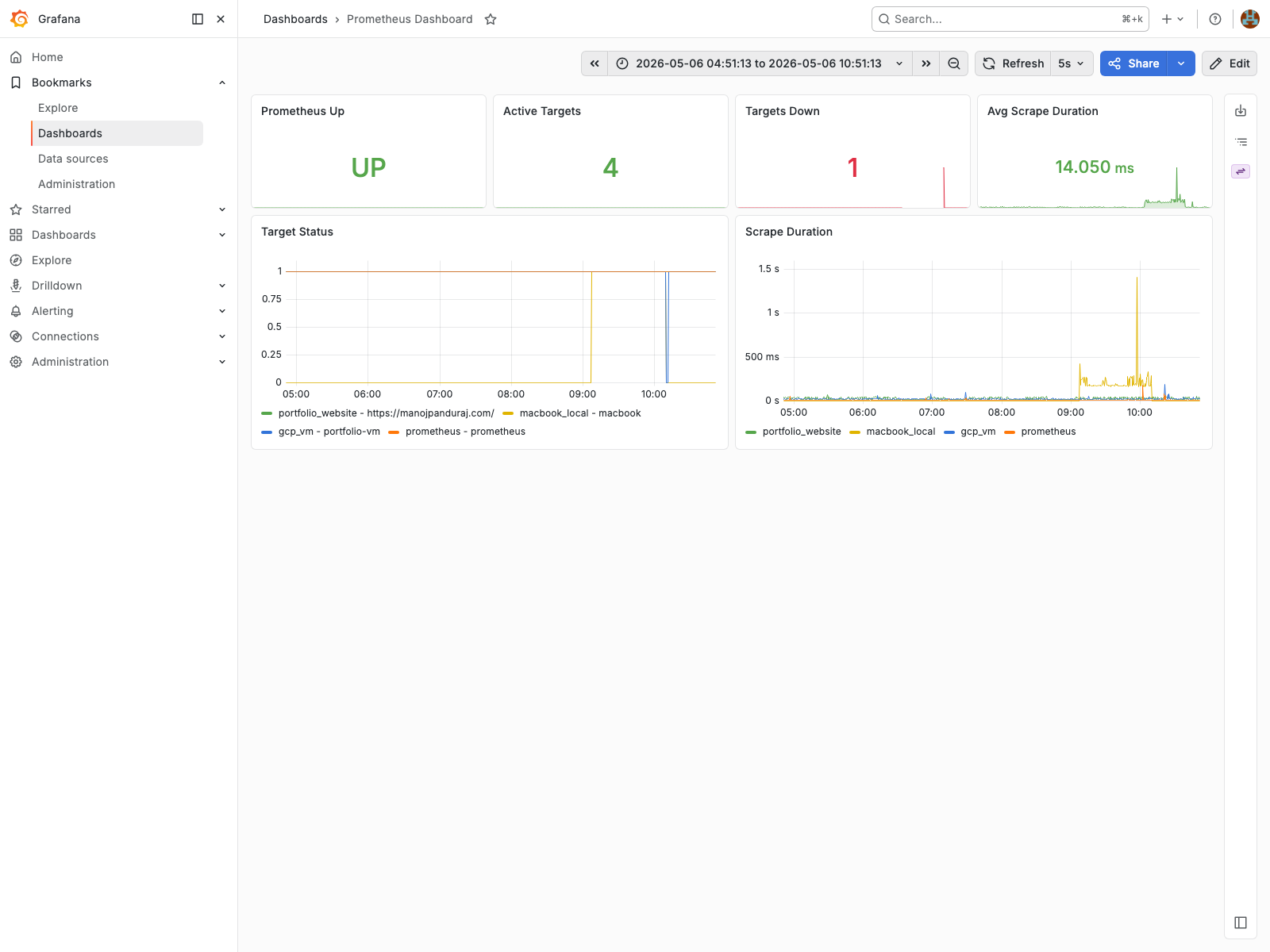
Prometheus Monitoring
Target health, scrape duration, failures, and monitoring pipeline metrics.
Slack Incident Alerts
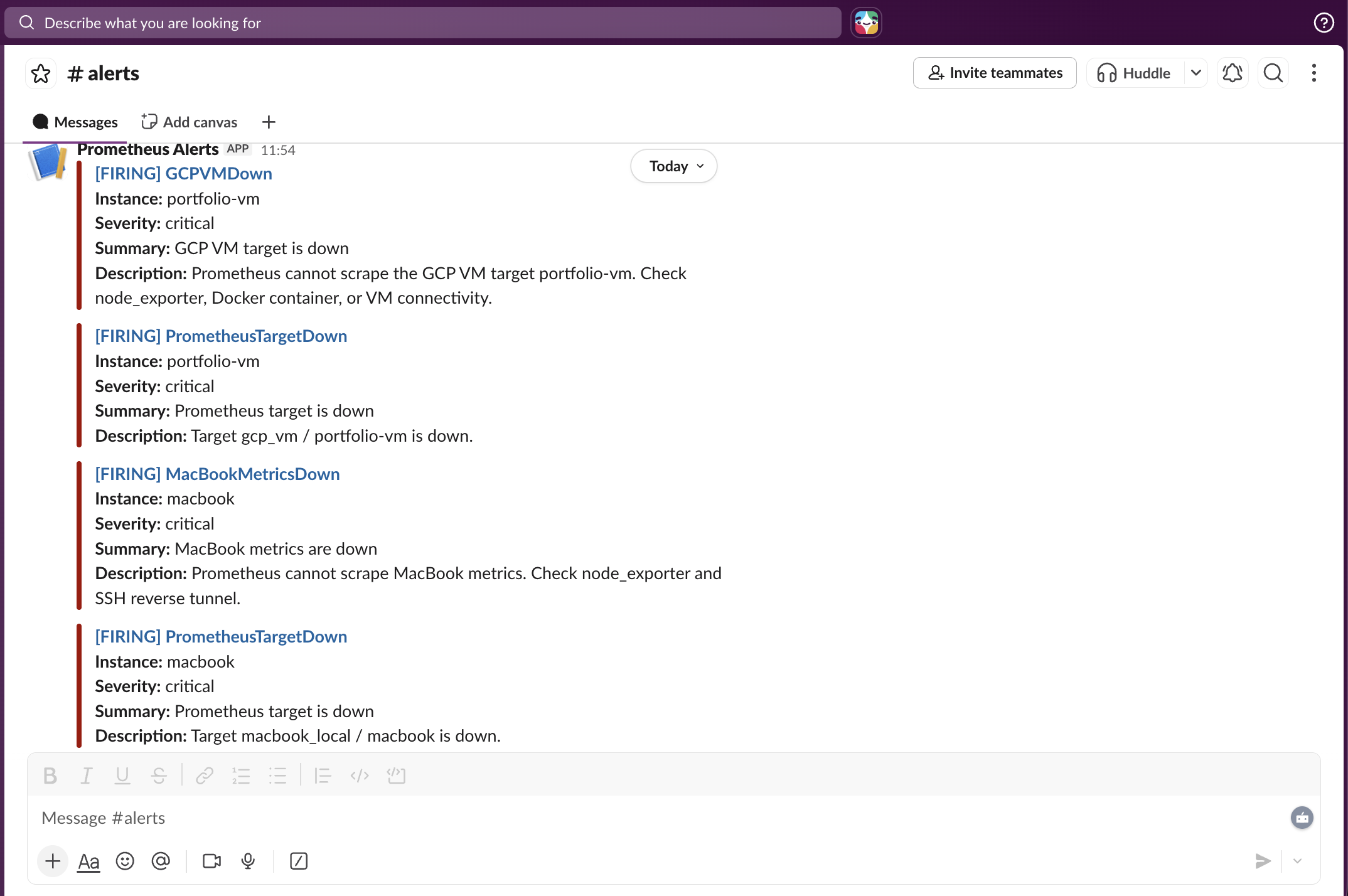
Firing Alerts
Real-time Slack alerts from Alertmanager.
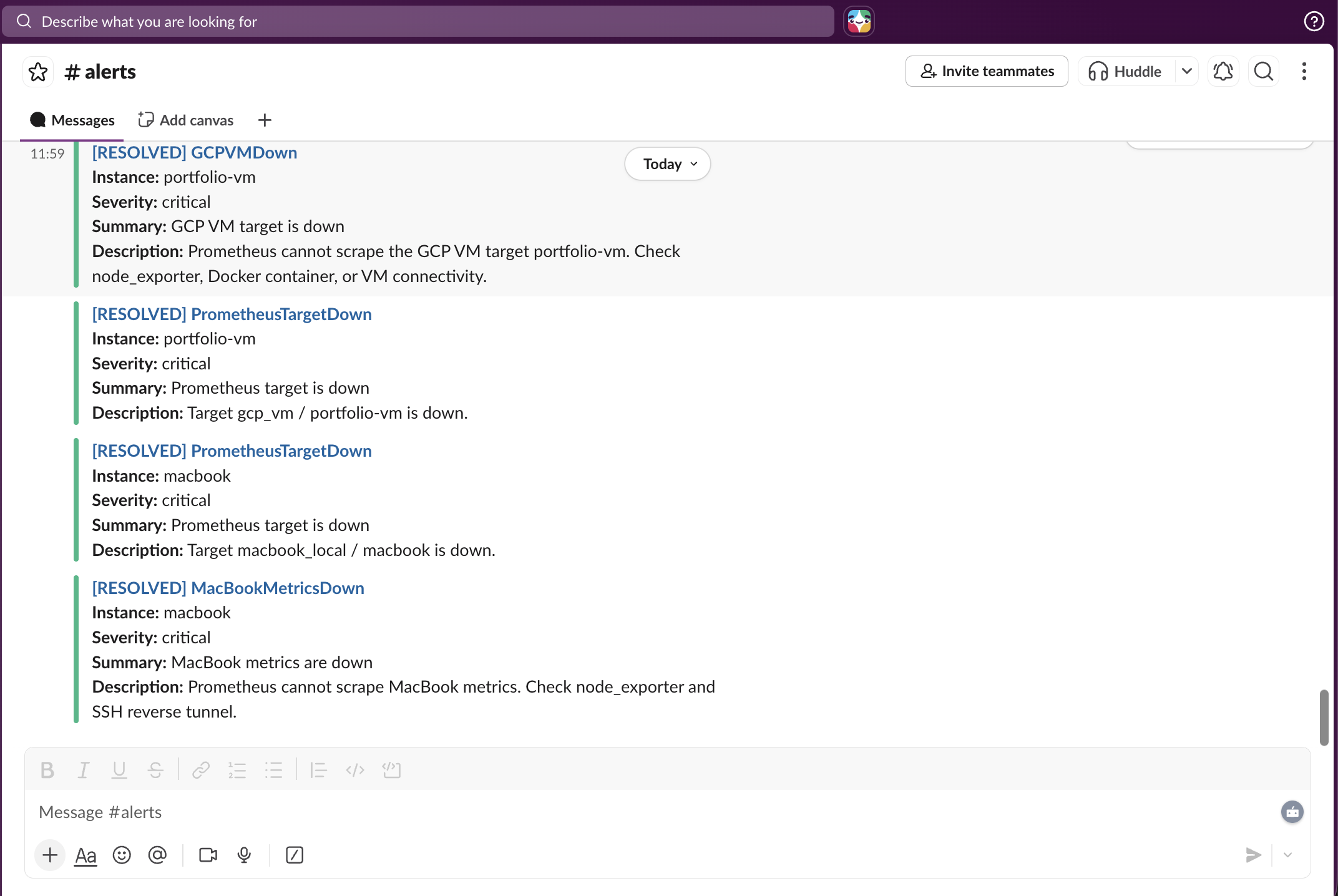
Resolved Alerts
Full alert lifecycle with automatic recovery notifications.
Incident Response Workflow
1. Alert
Slack receives incident notification.
2. Metrics
Analyze Grafana dashboards.
3. Logs
Search Loki logs for RCA.
4. Fix
Resolve infrastructure/service issue.
5. Recovery
Alertmanager sends resolved notification.
Core Competencies
Platform Engineering
Designing scalable and secure cloud-native infrastructure.
SRE & Reliability
Production support, incident response, RCA, and MTTR reduction.
Infrastructure Automation
Building reusable and repeatable infrastructure provisioning.
CI/CD Delivery
Automating build, test, and deployment workflows.
Observability
Monitoring, logging, alerting, and incident analysis.
Cloud Operations
Managing and optimizing multi-cloud environments.
Security
Implementing IAM, access control, and platform governance.
Ways of Working
Agile practices, documentation, and cross-team collaboration.
Platform Engineering Pillars
Architecting production environments where reliability meets velocity. My approach centers on automation, security, and deep observability.
Automation & IaC
Eliminating manual toil through modular Terraform modules and GitOps workflows. Ensuring repeatable, drift-aware infrastructure deployments.
Reliability & GKE
Managing production Kubernetes workloads with high-availability patterns. Optimizing cluster performance, autoscaling, and secure IAM/RBAC.
SRE & Observability
Reducing MTTR via Splunk and New Relic. Implementing proactive alerting, incident RCA, and data-driven platform optimizations.
Global Cloud Status
Technical Skills
Certifications
Google Cloud Associate Cloud Engineer
In ProgressAssociate-level certification focused on Google Cloud infrastructure, deployment, monitoring, and operations.
Expected Completion: May 2026
Google Cloud Professional Cloud Architect
PlannedAdvanced cloud architecture, scalability, reliability, and security design.
Planned Completion: End of Q2 2026
Certified Kubernetes Administrator (CKA)
PlannedKubernetes cluster administration, troubleshooting, networking, and production orchestration expertise.
Planned Completion: End of Q2 2026
HashiCorp Terraform Associate
PlannedInfrastructure as Code (IaC), automation, provisioning, and cloud infrastructure management using Terraform.
Planned Completion: End of Q2 2026
Education
M.Sc in Data Science
University of Roehampton, London, United Kingdom
B.Tech in Computer Science Engineering
Dayananda Sagar University, Bengaluru, India
MSc Data Science - Projects
Evolution of Last-Mile Delivery Efficiency & E-Commerce Logistics Performance
Explainable Credit Scoring Using Deep Learning & SHAP
European Airport Traffic Data Visualisation
Statistically Guided ML Pipeline for Diabetic Retinopathy Classification
Classification, Neural Networks & Heart Disease Prediction
Big Data Analytics for Lung Cancer Risk Prediction on GCP
Statistical Analysis Across Multiple Datasets
NETWORK
NODES
Global Communication Channels
GitHub
@manoj-panduraj
LinkedIn
Professional Network
Email
Direct Contact